Summary benchmarking and compilation in perspective
The compiler is sneaky, but there's order behind the magic of the JVM. This is all fascinating, but it's probably not the bottleneck in your application.
Perspective
Let’s take a step back. Benchmarking is all well and good, and it’s an interesting and informative exercise, but it may not always be appropriate.
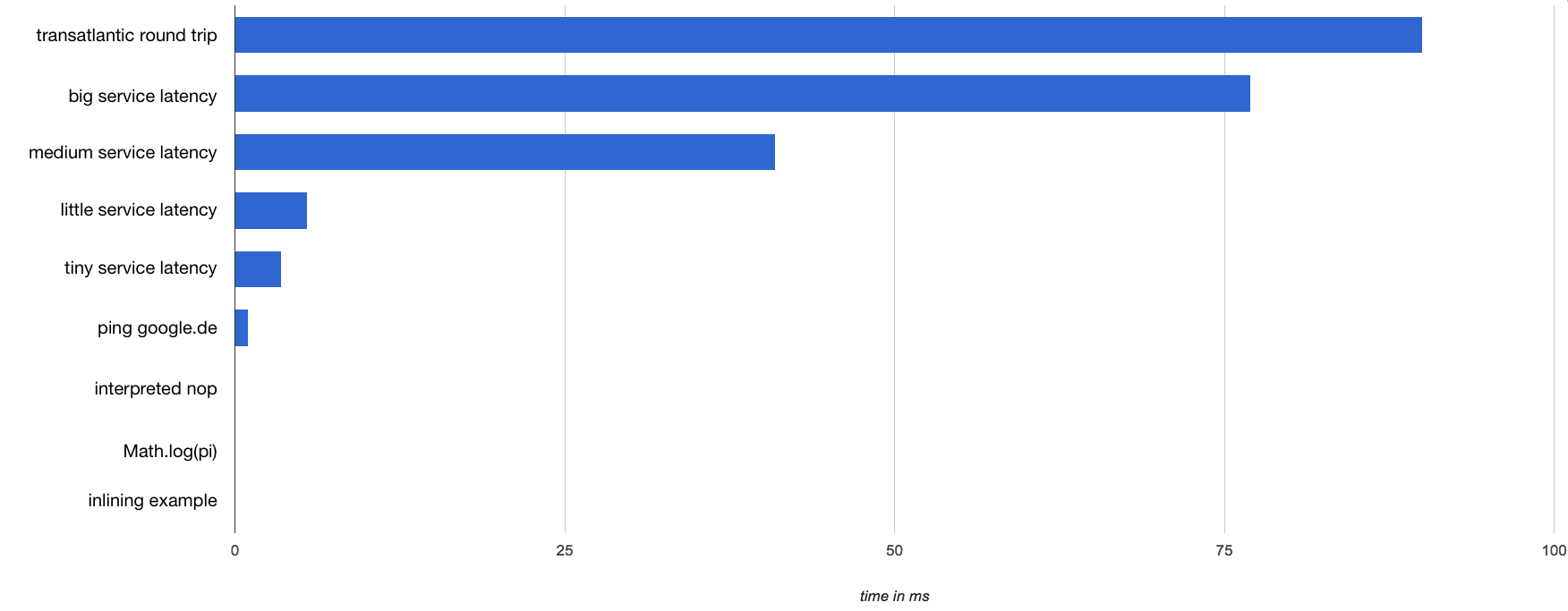
This chart shows timings of some operations that we might expect to see, including a transatlantic packet round trip at around 80ms. The service latencies are for different production services running where I work. Pinging Google takes only about one millisecond.
The other examples we benchmarked are on the order of a million times shorter; they don’t even get a pixel on this chart.
In many contexts you just don’t need to worry too much about benchmarking on this scale. For a service accessed over the Internet the time spent between your user and your data centre will always be the largest part of any perceived latency. In a microservices architecture, network hops between your machines will take the majority of the rest of the time.
So what should you do to speed up your code?
- Profile your system, on a larger scale, to find the bottlenecks. This isn’t microbenchmarking, this will likely be more like tracing to understand more complex systems.
- Architectural changes are always likely to dominate. If you have performance problems, first consider reducing network hops and database access, for example.
- Algorithmic decisions can often be the difference between fast and slow. Make sure that you haven’t gone accidentally quadratic.
- Microbenchmark part of an application, carefully, deliberately and scientifically, and only after profiling to find the hotspots in your code.
I claim that there’s a lot of educational value in benchmarking, for the reasons already outlined, but there’s certainly no point skipping earlier steps in search of performance.
What have we learned?
We’ve learned about Java and Scala types, a little about their similarities and differences. We looked at bytecode as the level of indirection allowing the JVM to implement “write-once run-anywhere”. And we’ve seen JMH not only as a tool for microbenchmarking, but also as a way to investigate what the JVM is doing under the covers.
Your code is a lie – there is such a distance between your IDE and your CPU that what goes in one end may scarcely resemble what actually runs. The compiler is sneaky, it implements a lot of optimisations that make our code fast. These optimisations are great in production, but can make it difficult to benchmark our code’s performance in a meaningful way.
There’s a lot going on that can look like magic. I hope that this short series strips away some of that to show some of the detail the sausage factory underneath.